Die neuesten MLA-C01 echte Prüfungsfragen, Amazon MLA-C01 originale fragen
Wiki Article
P.S. Kostenlose und neue MLA-C01 Prüfungsfragen sind auf Google Drive freigegeben von ITZert verfügbar: https://drive.google.com/open?id=1PoNaHoz76qUHf88Ne2AqctLoGWx2wCtu
Wenn Sie in kurzer Zeit mit weniger Mühe sich ganz effizient auf die Amazon MLA-C01 Zertifizierungsprüfung vorbereiten, benutzen Sie doch schnell die Schulungsunterlagen zur Amazon MLA-C01 Zertifizierungsprüfung. Sie werden von der Praxis bewährt. Viele Kandidaten haben bewiesen, dass man mit der Hilfe von ITZert die Prüfung 100% bestehen können. Mit ITZert können Sie Ihr Ziel erreichen und die beste Effekte erzielen.
Amazon MLA-C01 Prüfungsplan:
| Thema | Einzelheiten |
|---|---|
| Thema 1 |
|
| Thema 2 |
|
| Thema 3 |
|
| Thema 4 |
|
>> MLA-C01 Zertifizierungsprüfung <<
MLA-C01 Praxisprüfung & MLA-C01 Examsfragen
Wenn Sie die schwierige Amazon MLA-C01 Zertifizierungsprüfung bestehen wollen, ist es unmöglich für Sie bei der Vorbereitung keine richtige Schulungsunterlagen benutzen. Wenn Sie die ausgezeichnete Lernhilfe finden wollen, sollen Sie an ITZert diese Prüfungsunterlagen suchen. Wir ITZert haben sehr guten Ruf und haben viele ausgezeichnete Dumps zur Amazon MLA-C01 Prüfung. Und wir bieten kostenlose Demo aller verschieden Dumps. Wenn Sie suchen, ob ITZert Dumps für Sie geeignet sind, können Sie zuerst die Demo herunterladen und probieren.
Amazon AWS Certified Machine Learning Engineer - Associate MLA-C01 Prüfungsfragen mit Lösungen (Q101-Q106):
101. Frage
A company is gathering audio, video, and text data in various languages. The company needs to use a large language model (LLM) to summarize the gathered data that is in Spanish.
Which solution will meet these requirements in the LEAST amount of time?
- A. Use Amazon Comprehend and Amazon Translate to convert the data into English text. Use Amazon Bedrock with the Stable Diffusion model to summarize the text.
- B. Use Amazon Rekognition and Amazon Translate to convert the data into English text. Use Amazon Bedrock with the Anthropic Claude model to summarize the text.
- C. Train and deploy a model in Amazon SageMaker to convert the data into English text. Train and deploy an LLM in SageMaker to summarize the text.
- D. Use Amazon Transcribe and Amazon Translate to convert the data into English text. Use Amazon Bedrock with the Jurassic model to summarize the text.
Antwort: D
102. Frage
A company stores time-series data about user clicks in an Amazon S3 bucket. The raw data consists of millions of rows of user activity every day. ML engineers access the data to develop their ML models.
The ML engineers need to generate daily reports and analyze click trends over the past 3 days by using Amazon Athena. The company must retain the data for 30 days before archiving the data.
Which solution will provide the HIGHEST performance for data retrieval?
- A. Create AWS Lambda functions to copy the time-series data into separate S3 buckets. Apply S3 Lifecycle policies to archive data that is older than 30 days to S3 Glacier Flexible Retrieval.
- B. Organize the time-series data into partitions by date prefix in the S3 bucket. Apply S3 Lifecycle policies to archive partitions that are older than 30 days to S3 Glacier Flexible Retrieval.
- C. Put each day's time-series data into its own S3 bucket. Use S3 Lifecycle policies to archive S3 buckets that hold data that is older than 30 days to S3 Glacier Flexible Retrieval.
- D. Keep all the time-series data without partitioning in the S3 bucket. Manually move data that is older than 30 days to separate S3 buckets.
Antwort: B
Begründung:
Partitioning the time-series data by date prefix in the S3 bucket significantly improves query performance in Amazon Athena by reducing the amount of data that needs to be scanned during queries. This allows the ML engineers to efficiently analyze trends over specific time periods, such as the past 3 days. Applying S3 Lifecycle policies to archive partitions older than 30 days to S3 Glacier FlexibleRetrieval ensures cost- effective data retention and storage management while maintaining high performance for recent data retrieval.
103. Frage
An ML engineer wants to deploy an Amazon SageMaker AI model for inference. The payload sizes are less than 3 MB. Processing time does not exceed 45 seconds. The traffic patterns will be irregular or unpredictable.
Which inference option will meet these requirements MOST cost-effectively?
- A. Serverless inference
- B. Asynchronous inference
- C. Real-time inference
- D. Batch transform
Antwort: A
Begründung:
Amazon SageMaker Serverless Inference is designed for irregular or unpredictable traffic patterns. It automatically provisions and scales compute resources based on request volume and scales down to zero when idle, making it the most cost-effective option.
Serverless inference supports payloads up to 6 MB and request durations up to 60 seconds, which comfortably meets the stated constraints. Customers are billed only for actual compute usage during inference execution, not for idle capacity.
Asynchronous inference is intended for long-running jobs (up to 1 hour) and large payloads (up to 1 GB).
Real-time inference requires always-on instances, increasing cost during idle periods. Batch transform is designed for offline processing.
Therefore, serverless inference is the optimal choice.
104. Frage
A company wants to use large language models (LLMs) that are supported by Amazon Bedrock to develop a chat interface for the company ' s internal technical documentation. The company stores the documentation as dozens of text files that are several megabytes in total size. The company updates the text files often.
Which solution will meet these requirements MOST cost-effectively?
- A. Upload all the text files to an Amazon Bedrock knowledge base. Use the knowledge base to provide context when the chat interface makes calls to Amazon Bedrock.
- B. Create a new LLM on Amazon Bedrock. Train the new LLM on the original dataset and the company documentation. Make the new model available in Bedrock for calls from the chat interface.
- C. Use all the text files to fine tune a model in Amazon Bedrock. Use the fine-tuned model to process user prompts.
- D. Integrate the company documentation with Amazon Bedrock guardrails. Invoke the guardrails for all Amazon Bedrock calls from the chat interface.
Antwort: A
Begründung:
Option D is correct because Amazon Bedrock Knowledge Bases are designed for applications that need to answer questions using private documents without retraining or repeatedly fine-tuning a foundation model.
AWS documentation states that with Amazon Bedrock Knowledge Bases, you can build applications enriched by context retrieved from a knowledge base, and that this provides an out-of-the-box RAG solution. AWS also explicitly says that adding a knowledge base increases cost-effectiveness by removing the need to continually train your model to use your private data. That matches this use case very closely.
The question also says the documentation consists of text files that are only several megabytes total and are updated often. A retrieval-based approach is more economical and operationally simpler than creating a new model or repeatedly fine-tuning one whenever the documents change. AWS documentation for Bedrock knowledge bases describes adding data sources and running ingestion jobs to process and index the content, which is exactly the pattern needed for frequently updated internal documentation used by a chat interface.
The other options are not as cost-effective. Creating a new LLM is far beyond the need here. Guardrails help control model behavior and policy enforcement, but they do not serve as a document retrieval layer for internal documentation. Fine-tuning a model on frequently changing text files is usually more expensive and less flexible than using retrieval augmentation. For a modest-sized, frequently updated documentation corpus, the AWS-native and most cost-effective solution is to load the files into an Amazon Bedrock knowledge base and use it to provide context at inference time. Therefore, the best verified answer is D.
105. Frage
Hotspot Question
A company stores historical data in .csv files in Amazon S3. Only some of the rows and columns in the .csv files are populated. The columns are not labeled. An ML engineer needs to prepare and store the data so that the company can use the data to train ML models.
Select and order the correct steps from the following list to perform this task. Each step should be selected one time or not at all. (Select and order three.)
- Create an Amazon SageMaker batch transform job for data cleaning and
feature engineering.
- Store the resulting data back in Amazon S3.
- Use Amazon Athena to infer the schemas and available columns.
- Use AWS Glue crawlers to infer the schemas and available columns.
- Use AWS Glue DataBrew for data cleaning and feature engineering.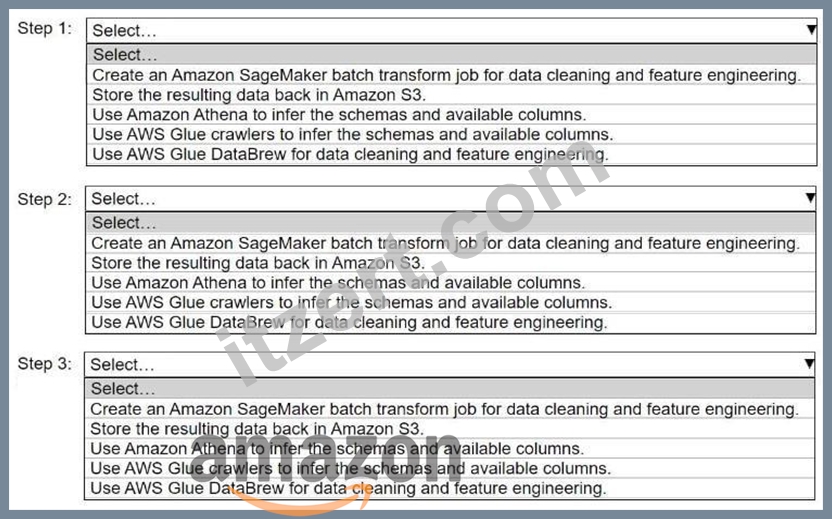
Antwort:
Begründung: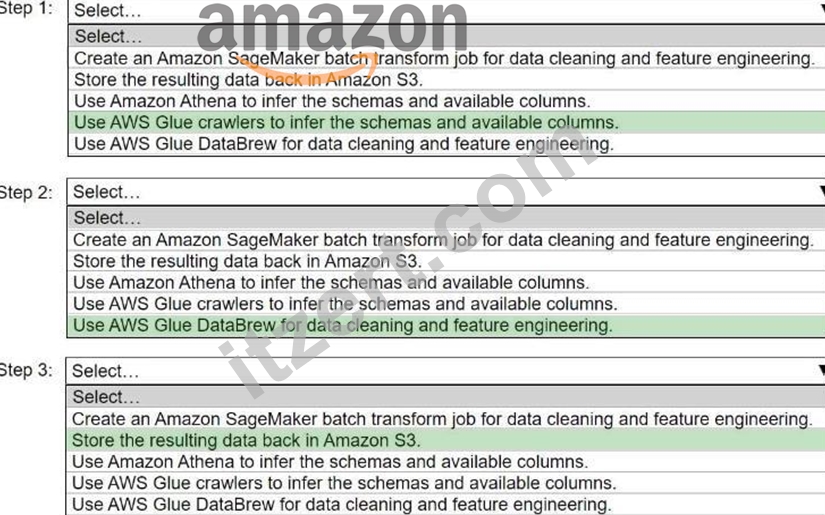
106. Frage
......
Wenn Sie IT-Angestellter sind, wollen Sie befördert werden? Wollen Sie ein IT-Technikexpert werden? Dann legen Sie doch die Amazon MLA-C01 Zertifizierungsprüfung ab! Sie wissen auch, wie wichtig diese Zertifizierung Ihnen ist. Sie sollen sich keine Sorgen darüber machen, die Prüfung zu bestehen. Sie soll auch an Ihrer Fähigkeit zweifeln. Wenn Sie sich an der Amazon MLA-C01 Zertifizierungsprüfung beteiligen, wenden Sie sich ITZert an. Er ist eine professionelle Schulungswebsite. Mit ihm können alle schwierigen Fragen lösen. Die Schulungsunterlagen zur Amazon MLA-C01 Zertifizierungsprüfung von ITZert können Ihnen helfen, die Amazon MLA-C01 Prüfung einfach zu bestehen. Er hat unzähligen Kandidaten geholfen. Wir garantieren Ihnen 100% Erfolg. Klicken Sie den ITZert und Sie können Ihren Traum verwirklichen.
MLA-C01 Praxisprüfung: https://www.itzert.com/MLA-C01_valid-copyright.html
- MLA-C01 Dumps Deutsch ???? MLA-C01 Dumps Deutsch ???? MLA-C01 Prüfungsfrage ???? Öffnen Sie ⇛ www.zertpruefung.ch ⇚ geben Sie ➥ MLA-C01 ???? ein und erhalten Sie den kostenlosen Download ????MLA-C01 Fragenkatalog
- MLA-C01 Lernhilfe ???? MLA-C01 Exam Fragen ???? MLA-C01 Buch ???? Geben Sie ➥ www.itzert.com ???? ein und suchen Sie nach kostenloser Download von ▶ MLA-C01 ◀ ????MLA-C01 Schulungsangebot
- Amazon MLA-C01 Quiz - MLA-C01 Studienanleitung - MLA-C01 Trainingsmaterialien ???? Öffnen Sie die Website ⏩ www.echtefrage.top ⏪ Suchen Sie ➽ MLA-C01 ???? Kostenloser Download ????MLA-C01 Prüfungen
- MLA-C01 Buch ???? MLA-C01 Prüfungsübungen ???? MLA-C01 Lernhilfe ???? Suchen Sie einfach auf ☀ www.itzert.com ️☀️ nach kostenloser Download von [ MLA-C01 ] ????MLA-C01 Prüfungen
- MLA-C01 Vorbereitungsfragen ???? MLA-C01 PDF Demo ???? MLA-C01 Online Praxisprüfung ???? Suchen Sie jetzt auf ( de.fast2test.com ) nach ➡ MLA-C01 ️⬅️ um den kostenlosen Download zu erhalten ????MLA-C01 Musterprüfungsfragen
- MLA-C01 Übungstest: AWS Certified Machine Learning Engineer - Associate - MLA-C01 copyright Prüfung ???? Erhalten Sie den kostenlosen Download von 【 MLA-C01 】 mühelos über “ www.itzert.com ” ????MLA-C01 Lernhilfe
- Die anspruchsvolle MLA-C01 echte Prüfungsfragen von uns garantiert Ihre bessere Berufsaussichten! ???? Öffnen Sie die Website ▶ www.deutschpruefung.com ◀ Suchen Sie ▶ MLA-C01 ◀ Kostenloser Download ????MLA-C01 Zertifizierungsantworten
- MLA-C01 Schulungsangebot ???? MLA-C01 Testfagen ???? MLA-C01 Quizfragen Und Antworten ???? Geben Sie ▶ www.itzert.com ◀ ein und suchen Sie nach kostenloser Download von ⏩ MLA-C01 ⏪ ????MLA-C01 Prüfungen
- MLA-C01 Übungsmaterialien - MLA-C01 Lernführung: AWS Certified Machine Learning Engineer - Associate - MLA-C01 Lernguide ???? Suchen Sie jetzt auf ➡ www.deutschpruefung.com ️⬅️ nach ⏩ MLA-C01 ⏪ um den kostenlosen Download zu erhalten ❤MLA-C01 Fragenkatalog
- MLA-C01 Prüfungsfrage ▛ MLA-C01 Zertifikatsfragen ???? MLA-C01 Kostenlos Downloden ⛅ Öffnen Sie die Website 【 www.itzert.com 】 Suchen Sie “ MLA-C01 ” Kostenloser Download ⓂMLA-C01 Fragenkatalog
- MLA-C01 Quizfragen Und Antworten ???? MLA-C01 Prüfungsübungen ???? MLA-C01 Musterprüfungsfragen ???? Suchen Sie auf ⏩ www.zertfragen.com ⏪ nach 「 MLA-C01 」 und erhalten Sie den kostenlosen Download mühelos ⚡MLA-C01 Online Praxisprüfung
- siobhanfbsb528456.tusblogos.com, maciebgco822887.vidublog.com, www.stes.tyc.edu.tw, jaspertxyj793904.activoblog.com, businessbookmark.com, albertqxsj951065.wikicarrier.com, lewisfmzl945566.wikilowdown.com, mattiedorm161193.p2blogs.com, anitamwyt675861.estate-blog.com, wildbookmarks.com, Disposable vapes
Übrigens, Sie können die vollständige Version der ITZert MLA-C01 Prüfungsfragen aus dem Cloud-Speicher herunterladen: https://drive.google.com/open?id=1PoNaHoz76qUHf88Ne2AqctLoGWx2wCtu
Report this wiki page